Originally published at cto.new
Introducing cto bench: The ground truth code agent benchmark

Most AI benchmarks are built backwards. Someone comes up with a problem set and measures how well agents solve them. The results are interesting, but they usually don’t tell you what matters: how agents perform on real work.
That's why we built cto.bench.
Instead of problem sets, we're building our benchmark on real end-to-end coding tasks. Every data point on cto bench comes directly from how cto.new users are actually using the models on our platform.
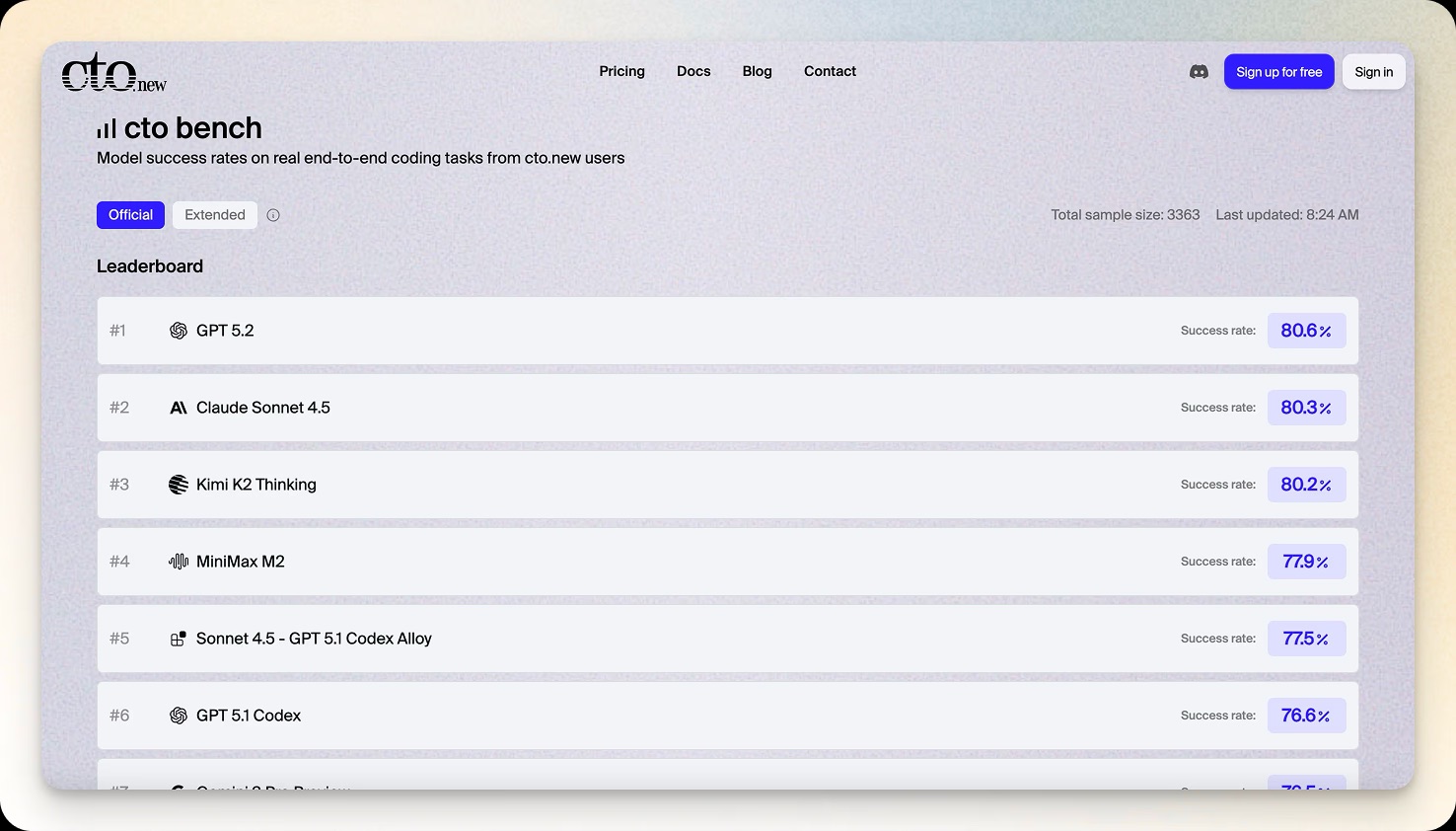
The methodology
We believe benchmarks should be transparent. As of this writing, we are using a rolling 72 hour average of PRs merged versus PRs made, presenting results for frontier models currently available on cto.new. If you’d like to dig deeper, you can read all the details on methodology right on the site at https://cto.new/bench.

If you want to know how well models perform in the real world, cto bench is updated every day. This is a living benchmark, and will evolve with usage patterns.
Check it out
Check out cto bench at https://cto.new/bench, and if you haven’t already, try the world’s first, and best, completely free AI code agent at https://cto.new, where GPT-5.3, Claude Sonnet 4.5 and Gemini 3 Pro and more are available at no cost.
Lastly, to discuss all things cto bench we’ve got a new dedicated channel in our Discord community called #cto-bench.